Note
Go to the end to download the full example code.
Benchmarking linear operators
In this tutorial, we demonstrate how to evaluate the run time and memory performance of linear operators. This allows to get a feeling for how expensive each operator is, compared to a gradient computation.
Warning
For pedagogical reasons, this example considers a small synthetic problem which may not reflect the relative cost of linear operators on larger problems. However, the following example can easily be applied to larger problems that are not executed when building the documentation.
Let’s get the imports out of the way.
import inspect
from itertools import product
from os import environ
from shutil import which
import matplotlib.pyplot as plt
from benchmark_execute import Benchmark
from benchmark_utils import (
_KFAC_LIKE,
LINOP_STRS,
MATVEC_LINOP_STRS,
RESULTDIR,
_get_precompute_ops,
add_gradient_reference,
display_name,
figpath,
save_environment_info,
)
from benchmark_utils import (
PROBLEM_STRS as ALL_PROBLEM_STRS,
)
from matplotlib.patches import Patch
from torch import cuda
from tueplots import bundles
Let’s also set up some variables that will be useful to generate and store results.
# In the execution with sphinx-gallery, __file__ is not defined and we need
# to set it manually using the trick from https://stackoverflow.com/a/53293924
if "__file__" not in globals():
__file__ = inspect.getfile(lambda: None)
# When running on RTD, we only want to execute the small example
ON_RTD = environ.get("READTHEDOCS", "False") == "True"
# Use LaTeX if available
USETEX = which("latex") is not None
# Devices to run the benchmark on
DEVICE_STRS = ["cuda"] if cuda.is_available() else ["cpu"]
# Whether to skip runs for which measurements already exist
SKIP_EXISTING = True
# Supported problems (use only the small MLP on RTD)
PROBLEM_STRS = ["synthetic_mnist_mlp"] if ON_RTD else ALL_PROBLEM_STRS
save_environment_info(RESULTDIR)
pytorch_version: 2.11.0+cu130
hostname: build-32619783-project-724984-curvlinops
Benchmark execution
The Benchmark class handles all measurements.
For each problem and device, we measure a reference gradient computation
and then each linear operator. Run time is measured in-process (minimum over
multiple repeats), while peak memory is measured in isolated subprocesses to
avoid allocation artifacts.
for problem_str, device_str in product(PROBLEM_STRS, DEVICE_STRS):
bench = Benchmark(problem_str, device_str, skip_existing=SKIP_EXISTING)
bench.run_reference()
for linop_str in LINOP_STRS:
bench.run_operator(linop_str)
[Time] Reference on synthetic_mnist_mlp and cpu (eager): 0.0397 s
[Time] Reference on synthetic_mnist_mlp and cpu (compiled): 0.0397 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --reference
STDOUT: [Memory] Reference gradient_and_loss (eager) on synthetic_mnist_mlp and cpu: 0.72 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --reference --compiled
STDOUT: [Memory] Reference gradient_and_loss (compiled) on synthetic_mnist_mlp and cpu: 0.80 GiB
STDERR:
[Time] Hessian on synthetic_mnist_mlp and cpu / matvec (eager): 0.1248 s
/home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/lib/python3.10/site-packages/torch/_inductor/lowering.py:1960: FutureWarning: `torch._prims_common.check` is deprecated and will be removed in the future. Please use `torch._check*` functions instead.
check(
[Time] Hessian on synthetic_mnist_mlp and cpu / matvec (compiled): 0.0992 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=Hessian
STDOUT: [Memory] Hessian (eager) on synthetic_mnist_mlp and cpu: 0.78 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=Hessian --compiled
STDOUT: [Memory] Hessian (compiled) on synthetic_mnist_mlp and cpu: 0.86 GiB
STDERR:
[Time] Generalized Gauss-Newton on synthetic_mnist_mlp and cpu / matvec (eager): 0.0935 s
/home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/lib/python3.10/site-packages/torch/_inductor/lowering.py:1960: FutureWarning: `torch._prims_common.check` is deprecated and will be removed in the future. Please use `torch._check*` functions instead.
check(
[Time] Generalized Gauss-Newton on synthetic_mnist_mlp and cpu / matvec (compiled): 0.0841 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=Generalized Gauss-Newton
STDOUT: [Memory] Generalized Gauss-Newton (eager) on synthetic_mnist_mlp and cpu: 0.75 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=Generalized Gauss-Newton --compiled
STDOUT: [Memory] Generalized Gauss-Newton (compiled) on synthetic_mnist_mlp and cpu: 0.82 GiB
STDERR:
[Time] Empirical Fisher on synthetic_mnist_mlp and cpu / matvec (eager): 0.0928 s
/home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/lib/python3.10/site-packages/torch/_inductor/lowering.py:1960: FutureWarning: `torch._prims_common.check` is deprecated and will be removed in the future. Please use `torch._check*` functions instead.
check(
[Time] Empirical Fisher on synthetic_mnist_mlp and cpu / matvec (compiled): 0.0839 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=Empirical Fisher
STDOUT: [Memory] Empirical Fisher (eager) on synthetic_mnist_mlp and cpu: 0.75 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=Empirical Fisher --compiled
STDOUT: [Memory] Empirical Fisher (compiled) on synthetic_mnist_mlp and cpu: 0.82 GiB
STDERR:
[Time] Monte-Carlo Fisher on synthetic_mnist_mlp and cpu / matvec (eager): 0.0944 s
/home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/lib/python3.10/site-packages/torch/_inductor/lowering.py:1960: FutureWarning: `torch._prims_common.check` is deprecated and will be removed in the future. Please use `torch._check*` functions instead.
check(
[Time] Monte-Carlo Fisher on synthetic_mnist_mlp and cpu / matvec (compiled): 0.0864 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=Monte-Carlo Fisher
STDOUT: [Memory] Monte-Carlo Fisher (eager) on synthetic_mnist_mlp and cpu: 0.75 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=Monte-Carlo Fisher --compiled
STDOUT: [Memory] Monte-Carlo Fisher (compiled) on synthetic_mnist_mlp and cpu: 0.81 GiB
STDERR:
[Time] EKFAC (hooks) on synthetic_mnist_mlp and cpu / matvec (eager): 0.1099 s
[Time] EKFAC (hooks) on synthetic_mnist_mlp and cpu / kfac_factors (eager): 0.0776 s
[Time] EKFAC (hooks) on synthetic_mnist_mlp and cpu / eigh (eager): 0.3092 s
[Time] EKFAC (hooks) on synthetic_mnist_mlp and cpu / eigenvalue_correction (eager): 0.0950 s
[Time] EKFAC (hooks) on synthetic_mnist_mlp and cpu / matvec (compiled): 0.1034 s
[Time] EKFAC (hooks) on synthetic_mnist_mlp and cpu / kfac_factors (compiled): 0.0781 s
[Time] EKFAC (hooks) on synthetic_mnist_mlp and cpu / eigh (compiled): 0.3093 s
[Time] EKFAC (hooks) on synthetic_mnist_mlp and cpu / eigenvalue_correction (compiled): 0.0945 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=EKFAC (hooks)
STDOUT: [Memory] EKFAC (hooks) (eager) on synthetic_mnist_mlp and cpu: 0.78 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=EKFAC (hooks) --compiled
STDOUT: [Memory] EKFAC (hooks) (compiled) on synthetic_mnist_mlp and cpu: 0.88 GiB
STDERR:
[Time] EKFAC inverse (hooks) on synthetic_mnist_mlp and cpu / matvec (eager): 0.1099 s
[Time] EKFAC inverse (hooks) on synthetic_mnist_mlp and cpu / kfac_factors (eager): 0.0772 s
[Time] EKFAC inverse (hooks) on synthetic_mnist_mlp and cpu / eigh (eager): 0.3082 s
[Time] EKFAC inverse (hooks) on synthetic_mnist_mlp and cpu / eigenvalue_correction (eager): 0.0953 s
[Time] EKFAC inverse (hooks) on synthetic_mnist_mlp and cpu / matvec (compiled): 0.1025 s
[Time] EKFAC inverse (hooks) on synthetic_mnist_mlp and cpu / kfac_factors (compiled): 0.0788 s
[Time] EKFAC inverse (hooks) on synthetic_mnist_mlp and cpu / eigh (compiled): 0.3087 s
[Time] EKFAC inverse (hooks) on synthetic_mnist_mlp and cpu / eigenvalue_correction (compiled): 0.0948 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=EKFAC inverse (hooks)
STDOUT: [Memory] EKFAC inverse (hooks) (eager) on synthetic_mnist_mlp and cpu: 0.78 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=EKFAC inverse (hooks) --compiled
STDOUT: [Memory] EKFAC inverse (hooks) (compiled) on synthetic_mnist_mlp and cpu: 0.88 GiB
STDERR:
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / matvec (eager): 0.1092 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / kfac_factors (eager): 0.0635 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / eigh (eager): 0.3069 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / eigenvalue_correction (eager): 0.0804 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / tracing (eager): 0.6100 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / matvec (compiled): 0.1026 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / kfac_factors (compiled): 0.0611 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / eigh (compiled): 0.3067 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / eigenvalue_correction (compiled): 0.0775 s
[Time] EKFAC (fx) on synthetic_mnist_mlp and cpu / tracing (compiled): 0.6139 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=EKFAC (fx)
STDOUT: [Memory] EKFAC (fx) (eager) on synthetic_mnist_mlp and cpu: 0.78 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=EKFAC (fx) --compiled
STDOUT: [Memory] EKFAC (fx) (compiled) on synthetic_mnist_mlp and cpu: 0.89 GiB
STDERR:
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / matvec (eager): 0.1105 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / kfac_factors (eager): 0.0639 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / eigh (eager): 0.3073 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / eigenvalue_correction (eager): 0.0810 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / tracing (eager): 0.6200 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / matvec (compiled): 0.1031 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / kfac_factors (compiled): 0.0612 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / eigh (compiled): 0.3083 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / eigenvalue_correction (compiled): 0.0777 s
[Time] EKFAC inverse (fx) on synthetic_mnist_mlp and cpu / tracing (compiled): 0.6064 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=EKFAC inverse (fx)
STDOUT: [Memory] EKFAC inverse (fx) (eager) on synthetic_mnist_mlp and cpu: 0.78 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=EKFAC inverse (fx) --compiled
STDOUT: [Memory] EKFAC inverse (fx) (compiled) on synthetic_mnist_mlp and cpu: 0.89 GiB
STDERR:
[Time] KFAC (hooks) on synthetic_mnist_mlp and cpu / matvec (eager): 0.0550 s
[Time] KFAC (hooks) on synthetic_mnist_mlp and cpu / kfac_factors (eager): 0.0781 s
[Time] KFAC (hooks) on synthetic_mnist_mlp and cpu / matvec (compiled): 0.0515 s
[Time] KFAC (hooks) on synthetic_mnist_mlp and cpu / kfac_factors (compiled): 0.0793 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=KFAC (hooks)
STDOUT: [Memory] KFAC (hooks) (eager) on synthetic_mnist_mlp and cpu: 0.75 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=KFAC (hooks) --compiled
STDOUT: [Memory] KFAC (hooks) (compiled) on synthetic_mnist_mlp and cpu: 0.84 GiB
STDERR:
[Time] KFAC inverse (hooks) on synthetic_mnist_mlp and cpu / matvec (eager): 0.0561 s
[Time] KFAC inverse (hooks) on synthetic_mnist_mlp and cpu / kfac_factors (eager): 0.0781 s
[Time] KFAC inverse (hooks) on synthetic_mnist_mlp and cpu / cholesky_inverse (eager): 0.0819 s
[Time] KFAC inverse (hooks) on synthetic_mnist_mlp and cpu / matvec (compiled): 0.0528 s
/home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/lib/python3.10/site-packages/torch/_inductor/lowering.py:1960: FutureWarning: `torch._prims_common.check` is deprecated and will be removed in the future. Please use `torch._check*` functions instead.
check(
[Time] KFAC inverse (hooks) on synthetic_mnist_mlp and cpu / kfac_factors (compiled): 0.0796 s
[Time] KFAC inverse (hooks) on synthetic_mnist_mlp and cpu / cholesky_inverse (compiled): 0.0833 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=KFAC inverse (hooks)
STDOUT: [Memory] KFAC inverse (hooks) (eager) on synthetic_mnist_mlp and cpu: 0.76 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=KFAC inverse (hooks) --compiled
STDOUT: [Memory] KFAC inverse (hooks) (compiled) on synthetic_mnist_mlp and cpu: 0.87 GiB
STDERR:
[Time] KFAC (fx) on synthetic_mnist_mlp and cpu / matvec (eager): 0.0559 s
[Time] KFAC (fx) on synthetic_mnist_mlp and cpu / kfac_factors (eager): 0.0639 s
[Time] KFAC (fx) on synthetic_mnist_mlp and cpu / tracing (eager): 0.2686 s
[Time] KFAC (fx) on synthetic_mnist_mlp and cpu / matvec (compiled): 0.0518 s
[Time] KFAC (fx) on synthetic_mnist_mlp and cpu / kfac_factors (compiled): 0.0615 s
[Time] KFAC (fx) on synthetic_mnist_mlp and cpu / tracing (compiled): 0.2610 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=KFAC (fx)
STDOUT: [Memory] KFAC (fx) (eager) on synthetic_mnist_mlp and cpu: 0.76 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=KFAC (fx) --compiled
STDOUT: [Memory] KFAC (fx) (compiled) on synthetic_mnist_mlp and cpu: 0.83 GiB
STDERR:
[Time] KFAC inverse (fx) on synthetic_mnist_mlp and cpu / matvec (eager): 0.0559 s
[Time] KFAC inverse (fx) on synthetic_mnist_mlp and cpu / kfac_factors (eager): 0.0638 s
[Time] KFAC inverse (fx) on synthetic_mnist_mlp and cpu / cholesky_inverse (eager): 0.0829 s
[Time] KFAC inverse (fx) on synthetic_mnist_mlp and cpu / tracing (eager): 0.2564 s
[Time] KFAC inverse (fx) on synthetic_mnist_mlp and cpu / matvec (compiled): 0.0519 s
/home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/lib/python3.10/site-packages/torch/_inductor/lowering.py:1960: FutureWarning: `torch._prims_common.check` is deprecated and will be removed in the future. Please use `torch._check*` functions instead.
check(
[Time] KFAC inverse (fx) on synthetic_mnist_mlp and cpu / kfac_factors (compiled): 0.0613 s
[Time] KFAC inverse (fx) on synthetic_mnist_mlp and cpu / cholesky_inverse (compiled): 0.0828 s
[Time] KFAC inverse (fx) on synthetic_mnist_mlp and cpu / tracing (compiled): 0.2571 s
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=KFAC inverse (fx)
STDOUT: [Memory] KFAC inverse (fx) (eager) on synthetic_mnist_mlp and cpu: 0.76 GiB
STDERR:
Running command: /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/envs/latest/bin/python /home/docs/checkouts/readthedocs.org/user_builds/curvlinops/checkouts/latest/docs/examples/basic_usage/benchmark_execute.py --problem=synthetic_mnist_mlp --device=cpu --linop=KFAC inverse (fx) --compiled
STDOUT: [Memory] KFAC inverse (fx) (compiled) on synthetic_mnist_mlp and cpu: 0.86 GiB
STDERR:
Run time visualization
We first visualize the matrix-vector product times for all operators, and then the precompute sub-phase breakdown for KFAC-like operators.
def _plot_eager_compiled_bars(ax, bench, linop_strs, key):
"""Plot eager/compiled horizontal bars, drawing the longer bar first.
Args:
ax: The matplotlib axes.
bench: The benchmark instance.
linop_strs: The linear operators.
key: Measurement key (e.g. ``"matvec"`` or ``"peakmem"``).
"""
eager_labeled = compiled_labeled = False
for idx, name in enumerate(linop_strs):
data = bench.load_operator(name)
eager_val = data["eager"][key]
compiled_val = data.get("compiled", {}).get(key)
# Build (label, value, color) tuples; sort descending so the longer
# bar is drawn first and the shorter one stays visible on top.
bars = [("eager", eager_val, "tab:blue")]
if compiled_val is not None:
bars.append(("compiled", compiled_val, "tab:cyan"))
bars.sort(key=lambda t: t[1], reverse=True)
labeled = {"eager": eager_labeled, "compiled": compiled_labeled}
for label_key, val, color in bars:
ax.barh(
idx,
val,
color=color,
label=label_key if not labeled[label_key] else None,
)
labeled[label_key] = True
eager_labeled, compiled_labeled = labeled["eager"], labeled["compiled"]
def visualize_matvec_benchmark(
bench: Benchmark, linop_strs: list[str]
) -> tuple[plt.Figure, plt.Axes]:
"""Visualize matvec times for all operators.
Shows eager times for all operators. For compilable operators, also shows
compiled times as an overlay.
Args:
bench: The benchmark instance (for loading results).
linop_strs: The linear operators.
Returns:
The figure and axes.
"""
reference = bench.load_reference()
fig, ax = plt.subplots()
_plot_eager_compiled_bars(ax, bench, linop_strs, "matvec")
ax.set_yticks(list(range(len(linop_strs))))
# Strip backend suffix — matvec is backend-independent
ax.set_yticklabels([display_name(n).replace(" (hooks)", "") for n in linop_strs])
ax.set_xlabel("Time [s]")
add_gradient_reference(ax, reference["eager"]["time"])
if "compiled" in reference:
ax.axvline(
reference["compiled"]["time"],
color="gray",
linestyle=":",
label="gradient (compiled)",
)
ax.legend(fontsize="small")
return fig, ax
def visualize_precompute_benchmark(
bench: Benchmark, linop_strs: list[str]
) -> tuple[plt.Figure, plt.Axes]:
"""Visualize precompute sub-phase breakdown for KFAC/EKFAC operators.
Args:
bench: The benchmark instance (for loading results).
linop_strs: The KFAC/EKFAC linear operators to plot.
Returns:
The figure and axes.
"""
kfac = [linop for linop in linop_strs if linop in _KFAC_LIKE]
fig, ax = plt.subplots()
precompute_colors = {
"kfac_factors": "tab:green",
"eigenvalue_correction": "tab:red",
"eigh": "tab:orange",
"cholesky_inverse": "tab:purple",
"tracing": "tab:brown",
}
precompute_labels = {
"kfac_factors": "Kronecker factors",
"eigenvalue_correction": "Eigen-correction",
"eigh": "Eigen-decomposition",
"cholesky_inverse": "Cholesky inverse",
"tracing": "FX tracing",
}
labels_shown = set()
bar_height = 0.3
bar_offset = 0.15
categories = [("eager", bar_offset, False), ("compiled", -bar_offset, True)]
for idx, name in enumerate(kfac):
sub_ops = _get_precompute_ops(name)
operator_data = bench.load_operator(name)
for category, y_off, is_compiled in categories:
cat_data = operator_data.get(category, {})
left = 0.0
for op in sub_ops:
if op == "tracing":
continue
t = cat_data.get(op, float("nan"))
label = precompute_labels[op] if op not in labels_shown else None
color = precompute_colors[op]
bar_kwargs = dict(color=color, alpha=0.5 if is_compiled else 1.0)
ax.barh(
idx + y_off,
width=t,
left=left,
label=label,
height=bar_height,
**bar_kwargs,
)
labels_shown.add(op)
left += t
ax.set_yticks(list(range(len(kfac))))
ax.set_yticklabels([display_name(n) for n in kfac])
ax.set_xlabel("Time [s]")
ax.set_xscale("log")
reference = bench.load_reference()["eager"]["time"]
add_gradient_reference(ax, reference)
handles, legend_labels = ax.get_legend_handles_labels()
handles.append(Patch(facecolor="black", alpha=0.5))
legend_labels.append("Compiled")
fig.legend(
handles,
legend_labels,
loc="outside lower center",
ncol=3,
)
return fig, ax
Let’s now visualize the results. We first show the matrix-vector product times.
plot_config = bundles.icml2024(column="full" if ON_RTD else "half", usetex=USETEX)
plt.rcParams["savefig.bbox"] = "tight"
kfac_linops = [linop for linop in LINOP_STRS if linop in _KFAC_LIKE]
for problem_str, device_str in product(PROBLEM_STRS, DEVICE_STRS):
bench = Benchmark(problem_str, device_str)
with plt.rc_context(plot_config):
fig, ax = visualize_matvec_benchmark(bench, MATVEC_LINOP_STRS)
plt.savefig(
figpath(problem_str, device_str, metric="time_matvec"),
bbox_inches="tight",
)

And the precompute sub-phase breakdown for KFAC-like operators.
for problem_str, device_str in product(PROBLEM_STRS, DEVICE_STRS):
bench = Benchmark(problem_str, device_str)
with plt.rc_context(plot_config):
fig, ax = visualize_precompute_benchmark(bench, kfac_linops)
plt.savefig(
figpath(problem_str, device_str, metric="time_precompute"),
bbox_inches="tight",
)

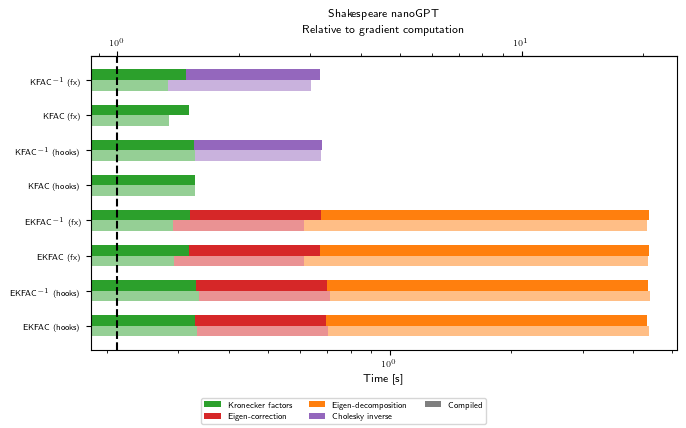
As hinted at in the introduction, the numbers we observe in this pedagogical example may not reflect the relative cost of linear operators on larger problems and GPUs. However, we should see a rough tendency that Hessian-vector products are more costly than GGN-vector products, and that KFAC costs only a few gradients to pre-compute, while being very cheap to multiply with. Also, inverting KFAC adds some additional run time.
Memory visualization
The peak memory benchmark results are collected alongside the run time measurements
by the Benchmark class. Memory measurements are run
in separate Python sessions to avoid allocation artifacts.
def visualize_peakmem_benchmark(
bench: Benchmark, linop_strs: list[str]
) -> tuple[plt.Figure, plt.Axes]:
"""Visualize the peak memory benchmark results.
Shows eager peak memory for all operators. For compilable operators, also
shows compiled peak memory as an overlay.
Args:
bench: The benchmark instance (for loading results).
linop_strs: The linear operators.
Returns:
The figure and axes of the plot.
"""
reference = bench.load_reference()
fig, ax = plt.subplots()
ax.set_xlabel("Peak memory [GiB]")
_plot_eager_compiled_bars(ax, bench, linop_strs, "peakmem")
ax.set_yticks(list(range(len(linop_strs))))
ax.set_yticklabels([display_name(n) for n in linop_strs])
add_gradient_reference(ax, reference["eager"]["peakmem"])
if "compiled" in reference:
ax.axvline(
reference["compiled"]["peakmem"],
color="gray",
linestyle=":",
label="gradient (compiled)",
)
ax.legend(fontsize="small")
return fig, ax
Let’s visualize the peak memory consumption.
for problem_str, device_str in product(PROBLEM_STRS, DEVICE_STRS):
bench = Benchmark(problem_str, device_str)
with plt.rc_context(plot_config):
fig, ax = visualize_peakmem_benchmark(bench, LINOP_STRS)
plt.savefig(
figpath(problem_str, device_str, metric="peakmem"), bbox_inches="tight"
)
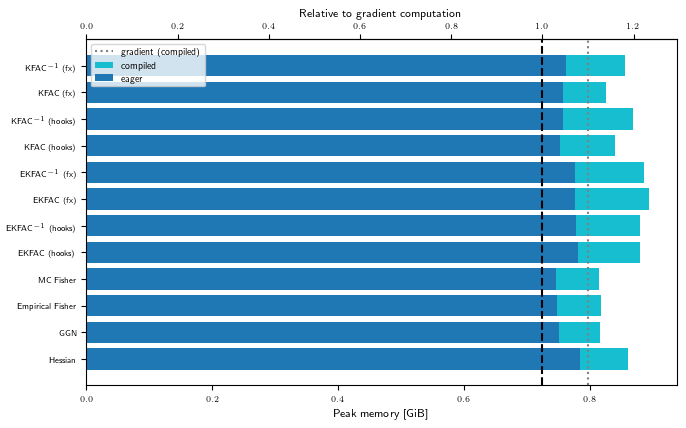
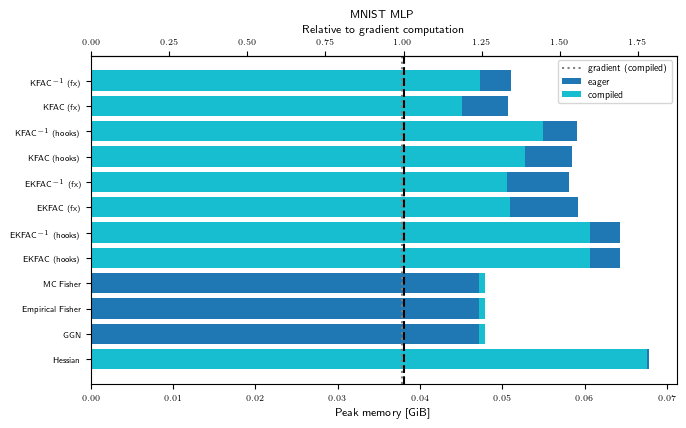
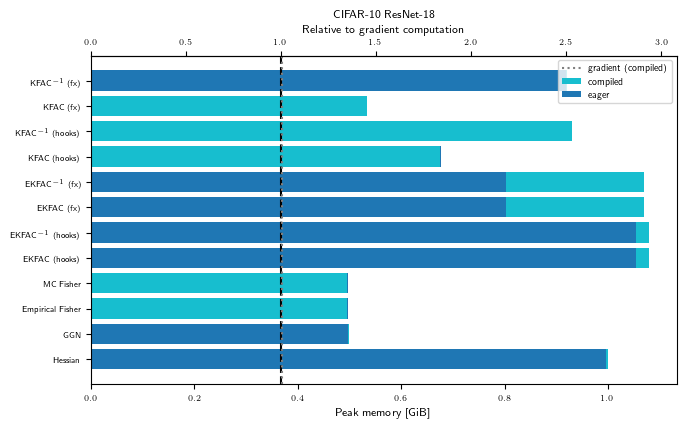
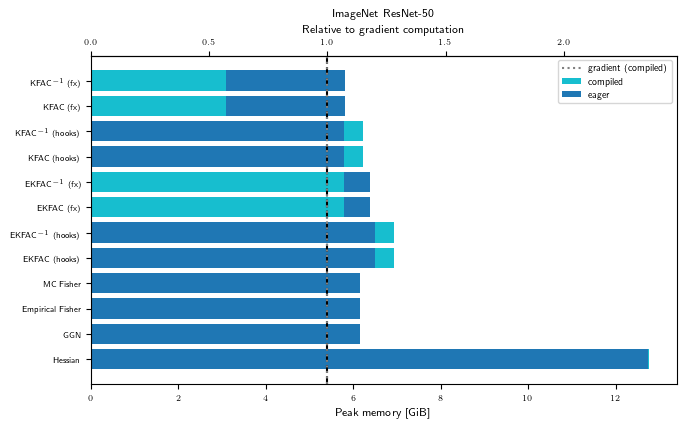
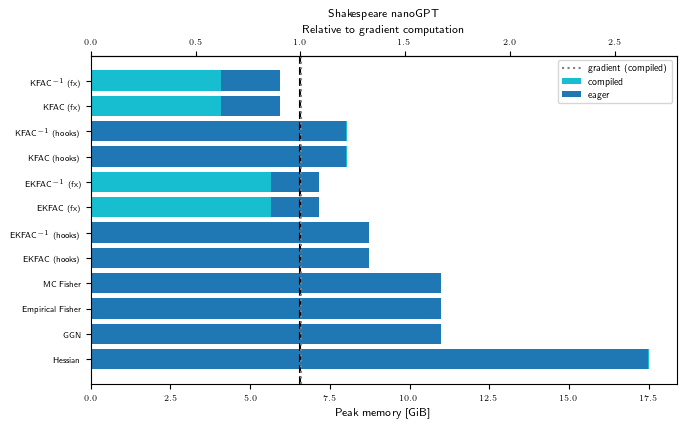
As hinted at in the introduction, the numbers we observe in this pedagogical example may not reflect the relative memory consumption on larger problems and GPUs.
Conclusion
In this tutorial, we have demonstrated how to evaluate the run time and memory performance of linear operators. This allows to get a feeling for how expensive each operator is, compared to a gradient computation.
While we only looked at a small synthetic problem, the same methodology can be applied to larger problems, as shown below.
GPU benchmark results
The plots above were generated on CPU for a small MLP on synthetic MNIST. Below, we show benchmark results that were pre-computed on a GPU for all supported problems.
PROBLEM_TITLES = {
"synthetic_mnist_mlp": "MNIST MLP",
"synthetic_cifar10_resnet18": "CIFAR-10 ResNet-18",
"synthetic_imagenet_resnet50": "ImageNet ResNet-50",
"synthetic_shakespeare_nanogpt": "Shakespeare nanoGPT",
}
Matvec times (GPU)
for problem_str in ALL_PROBLEM_STRS:
gpu_bench = Benchmark(problem_str, "cuda")
with plt.rc_context(plot_config):
fig, ax = visualize_matvec_benchmark(gpu_bench, MATVEC_LINOP_STRS)
ax.set_title(PROBLEM_TITLES[problem_str])
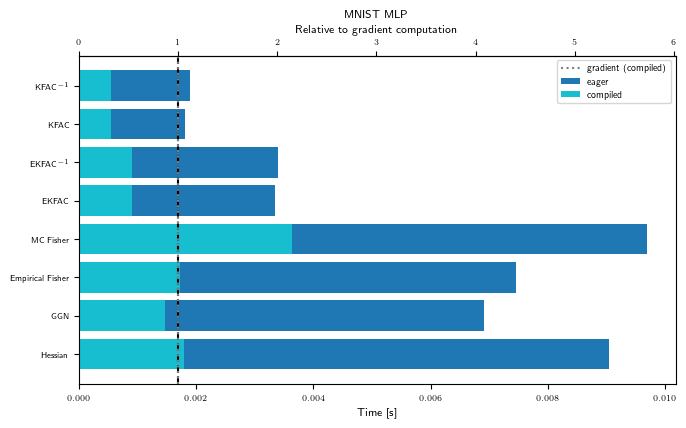
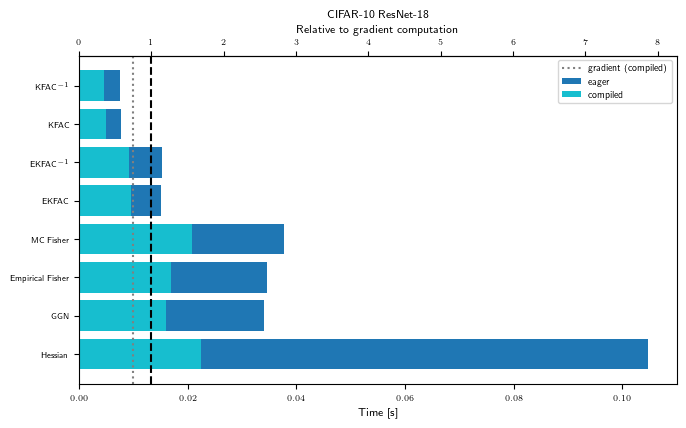
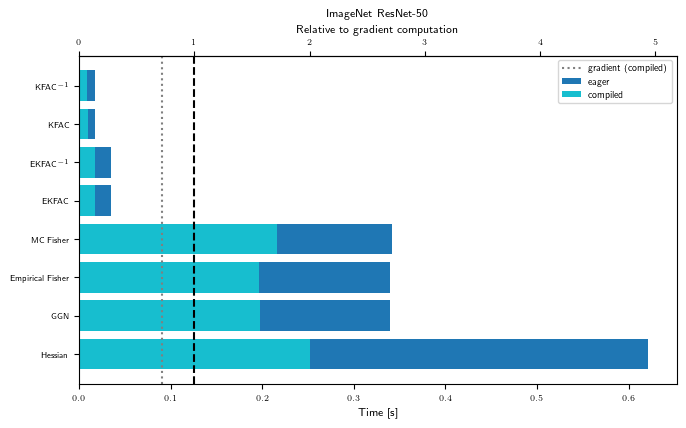
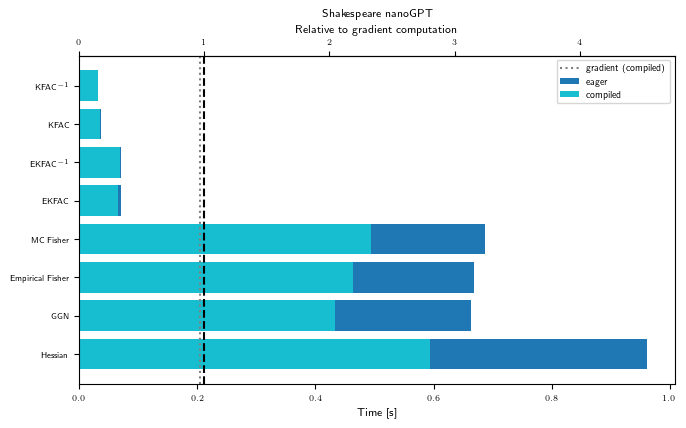
Precompute breakdown (GPU)
for problem_str in ALL_PROBLEM_STRS:
gpu_bench = Benchmark(problem_str, "cuda")
with plt.rc_context(plot_config):
fig, ax = visualize_precompute_benchmark(gpu_bench, kfac_linops)
ax.set_title(PROBLEM_TITLES[problem_str])
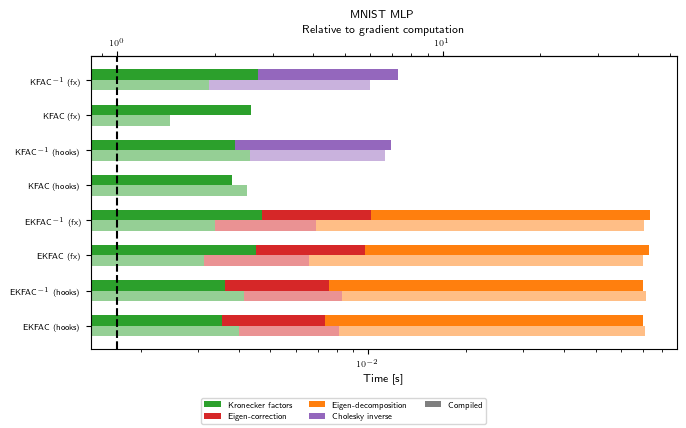
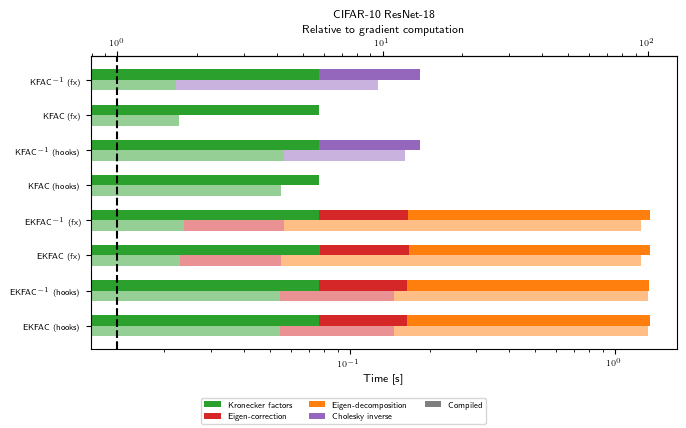
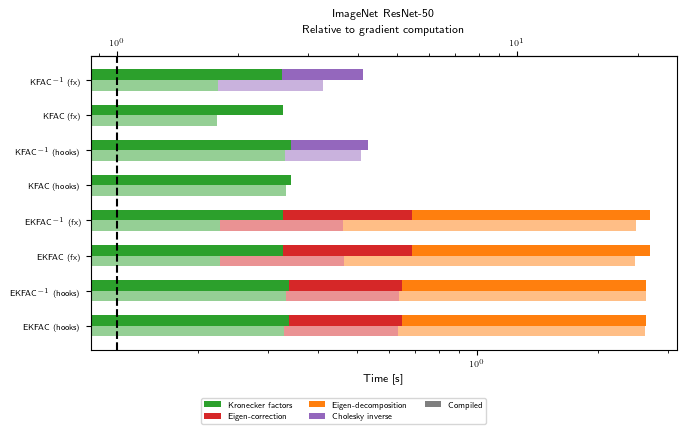
Peak memory (GPU)
for problem_str in ALL_PROBLEM_STRS:
gpu_bench = Benchmark(problem_str, "cuda")
with plt.rc_context(plot_config):
fig, ax = visualize_peakmem_benchmark(gpu_bench, LINOP_STRS)
ax.set_title(PROBLEM_TITLES[problem_str])
Total running time of the script: (8 minutes 25.499 seconds)